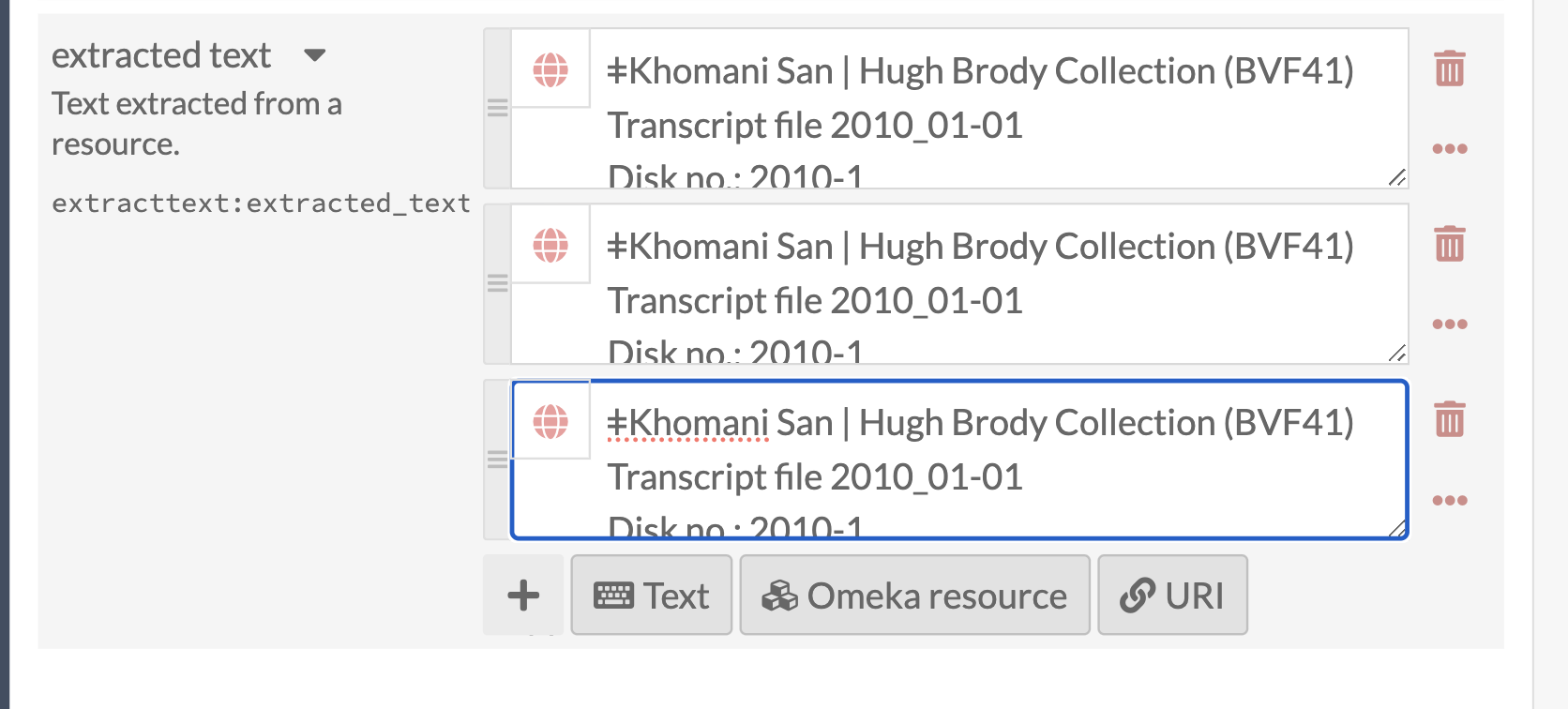
I have Extract Text version 1.2.1 on Omeka S 3.2.1 and I have encountered that sometimes, when importing PDF documents, I get multiple entries of the same thing in the extracted_text for a single PDF file.
I do not have any more information from the logs, and I can’t seem to spot the pattern of when there is more than one entry created and when not. Could this have an impact on the database?
I am curious if there is a way for me to edit these, or remove all but one entry, and also ensure I only get one entry in the future?
Many thanks
That is strange. This module should not create multiple values. Does this happen only on certain PDFs, or does it happen randomly? Try adding several PDFs to see if a pattern emerges.
Upgrading to the most recent Omeka S version may resolve this. We fixed a bug in 4.0.2 that may be related to this unusual behavior.
Another thing to look into is possible interactions with other modules. Try deactivating all modules except ExtractText (and whatever importer you may be using) and see if the problem persists.
Thanks a lot for the quick response. We might only look into upgrading to Omeka S 4 next year, so in the meantime I will do some more experiments that you suggested to see if I can spot a pattern.