I’ve been working on updating our metadata. First by aligning the values with Suggested Values.
But in some cases, the simple text value had a qualifier directly in it. I separated the values from their qualifiers, so far so good.
Now I’m thinking of a way to add those already existing qualifiers. My thinking goes like this:
Creating as many resources as they’re gonna be qualifiers in the resource table.
Adding the resource id list to the value annotation table.
Creating values with the actual qualifying value in the value table with their respective resource-id.
Finally, adding the resource id to the values that are the subject of the qualifications.
I haven’t checked yet if it would work, I just want to share this in hopes that somebody knows if it can work or has an easier way of doing things (I mean, it’s not that hard technically). For now it doesn’t seem CSV Import allows for annotations?
Just so I’m sure we’re on the same page, when you say qualifications here, you’re thinking of stuff you’d put into value annotations? Maybe a simple example of what you’re working with might help.
You’re right that the CSV Import module currently doesn’t handle annotations. If it did, do you have a vision of how you’d see that working (the complicating factor for annotations is that they must not only attach to a specific resource, but also to a specific value within that resource, and feasibly doing that mapping within a simple CSV is a little tricky).
Hello,
Annotations feature is a great addition to Omeka S and I think the ability to import annotations would be very useful! I will try to think of a way of doing it, as you are asking, and I will come back with my thoughts later, hopefully.
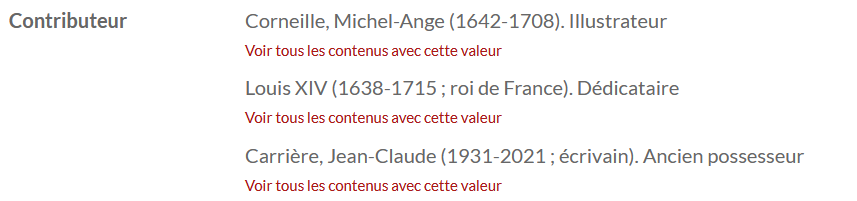
We have several dcterms:contributor values each with a specific role (Illustrator, previous owner, etc.).
Now, I am going to extract those values directly from the database, split the actual agent from their role so that I can align the agent with a valuesuggest vocabulary (thanks to the Reconcile option of OpenRefine), and import them back into the value table. But for their role/qualifier, which is going to become the annotation, I was wondering how to create those new annotation at the same time. My thinking was that since the value links to its annotation and not the other way round, I need first to make a CSV of these annotations, load it in the value table and then link back the annotated value to its annotation. My concern was if creating annotated values this way would transfer them to the resource and annotation-values table: the annotation-value-id would simply be created by incrementing by one from the latest resource id. Should I try to do it the other way round? (i.e. importing new resources of value annotation type, and then adding their id to the value annotation table and finally uploading them to the value table).
Anyway I’m going to test it as soon as I find the time.
As to how CSV Import could be used with value annotation (from an end-user perspective): I imagine it could work as a “mixed resource” thing. You would ask the importer to create a column for the value, and a column for the annotation (no multiple values allowed in the same cell this time) and in the “annotation-specific data” parameters of the import you detail to which column it is linked.