Note that I don’t think the PDF Text plugin is available for Omeka S as of yet. I extracted the text using another utility then simply uploaded this to the item metadata.
Honestly, I haven’t made much progress on this project. I am going to try once more, but with a different EC2 instance that has more available memory. If it can serve the pages with my text (hidden, using the updated Hide Properties module) relatively quickly I will just go that route. If not, I’ll have to reevaluate my options.
I have not yet tried the Solr plugin, but as we have discussed above, this will only improve the existing search. I still need the text in the item metadata for the search to work at all, and that is the sticking point for me with these long, long texts.
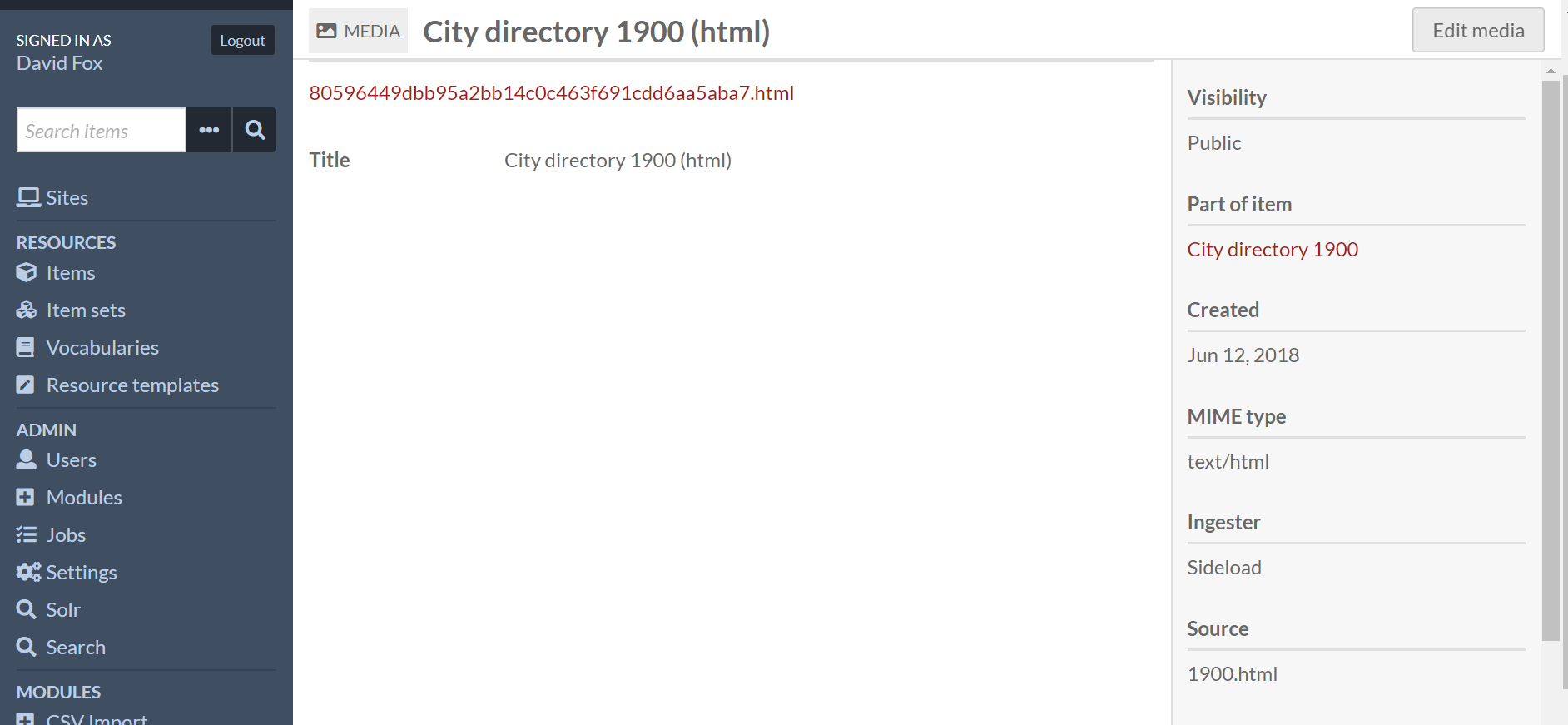
@pols12 I installed the Solr and Search plugin and confirmed that everything was working by adding items and ensuring that documents were being added to my Solr index. I then added an HTML version of one of my items as ‘media.’ I noticed that the number of documents in my index did not increase, and I was still unable to search the text of this HTML file.
Did I add the HTML file incorrectly?
I have installed version 0.4.0 of both the Solr and Search modules.
Hmm, it seems I may have misunderstood the issue. So I have my new search page configured to use Solr. And from here I can’t even search the metadata. So the issue is likely a bit more general than what I described above regarding the HTML file.
I do see the correct number of documents in my Solr index, but they are seemingly empty documents. So, I guess I have failed to set up indexing correctly. I’ll keep hacking at it.
Hi.
Could you tell me if, in our experience, the PDF Text plugin is working also with other languages than English? I’ve installed it, but I’m not sure it’s working for Italian and Esperanto, f.i…
Thanks
Biblibre hasn’t release a version including those improvements yet. You can either use Biblibre’s dev version (from Github, use “clone or download” button) or Daniel-KM’s last release which includes some other improvements and fixes.
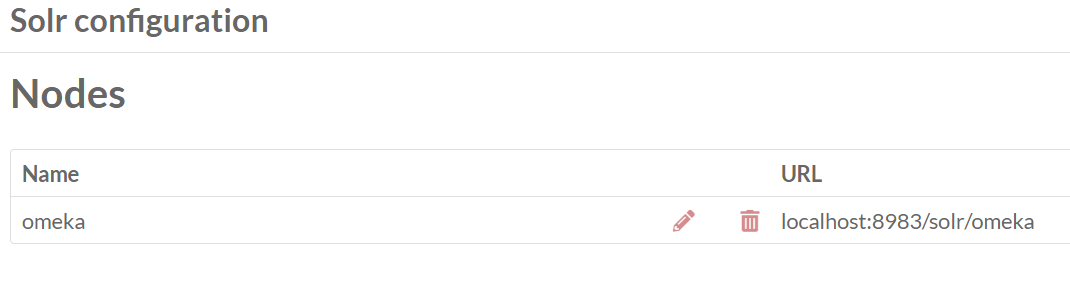
You have to configure the indexation: you need to map resource properties with Solr fields. In Admin navigation, choose Solr. Then, click on Mapping icon (third icon) of your Solr node. Choose Item and press “Add new mapping” to specify for each property a Solr dynamic field and a field name.
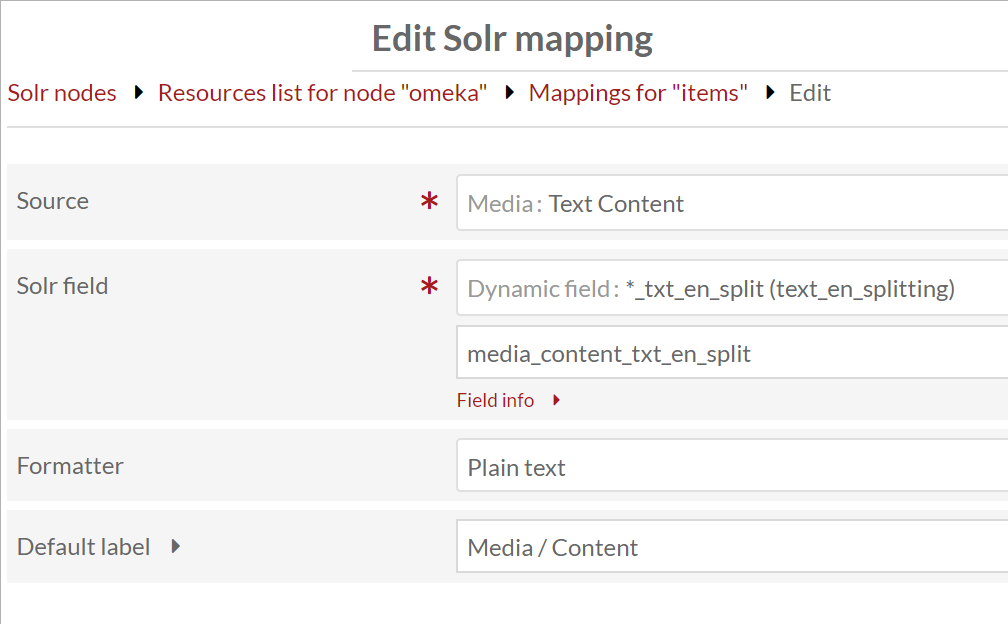
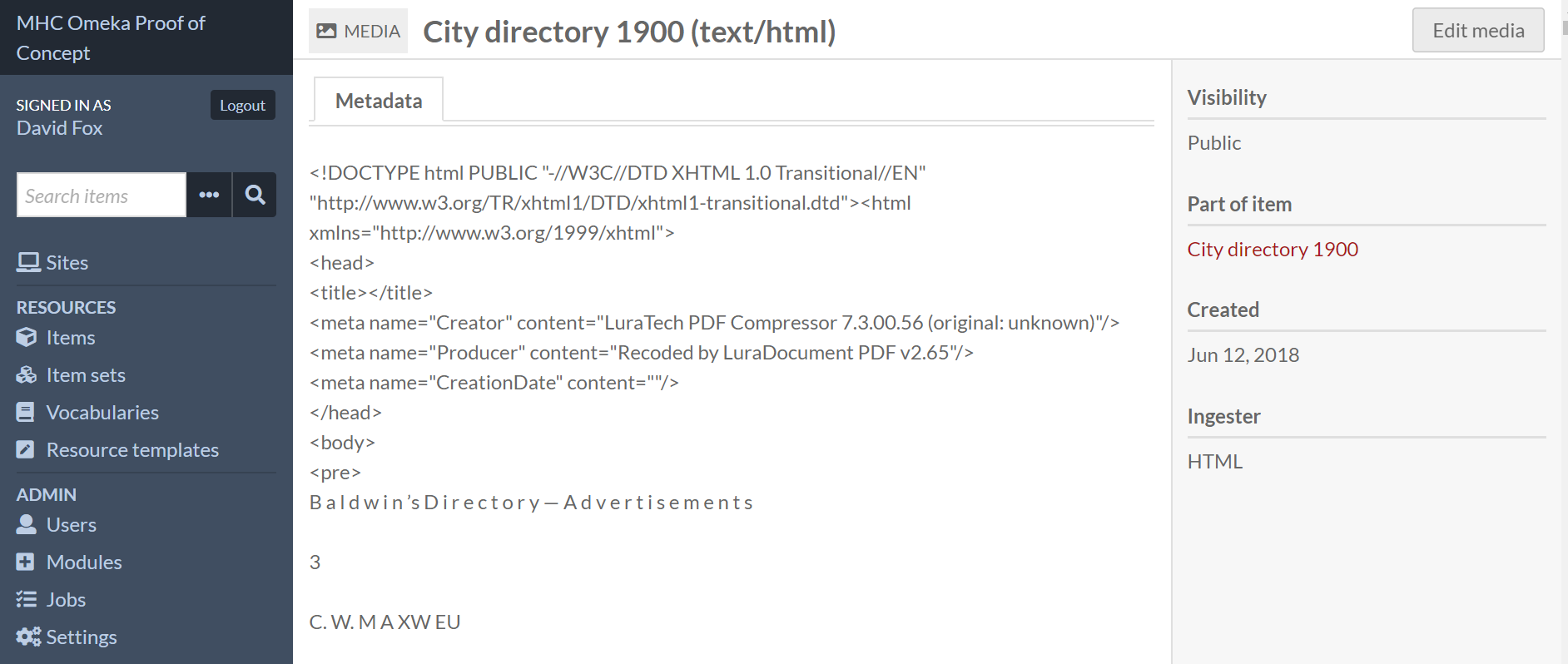
For HTML Media content, in Source you have to choose “HTML content” under “Media” group.
Also, if your media contains HTML tags, you should probably use “Plain text” value formatter to avoid HTML markup indexing.
Note I think it doesn’t work if your media is ingested as a file, even HTML file (but I haven’t test). You should use HTML ingester for your media.
Is there a sample Solr config that might clue me in to the exact resource names coming from Omeka? I’m assuming these are things like Title or Description?
Also, what is the safest way of upgrading a module in place? My assumption is something like: 1) uninstall module 2) rename module folder on server in case we need to rollback 3) download and extract new version 4) install and configure.
I’m not sure I’ve understood you. I believe that Daniel-KM’s version automatically configure basic Dublin Core properties like Title and Description. In Mapping form, you can choose Omeka property in “Source” field. The first displayed properties come from Omeka internal vocabulary (resource author, resource date creation…). Other properties are displayed like this: voc:prop where voc is the vocabulary prefix and prop is the property name; e.g. dcterms:title.
You are not obliged to uninstall module. You can make a backup of your module directory, but do not keep it in your /modules/ directory, even renamed. If the new version has a effective new higher number, Uninstall and Disable buttons are replaced by Update button. Use this button to reactivate the updated module.
Ah, I missed the mapping form. On my version the ‘mapping’ icon is missing. If you move your mouse over the empty space where it should be you can find the link. Perhaps my icon will be restored after I upgrade. Here’s what I was seeing:
Also, thanks for your tips about how to add the HTML correctly. I will try these as well.
Thank you to everyone who has helped me thus far. I am taking notes and will produce some document for posterity. I am sure there are others who want to do something similar, but who, like myself, lack pretty much all the requisite skills.
I have confirmed that HTML ingested as a file is not indexed, and that data added via HTML ingester is indexed.
I was happily using a combination of CSV Import and File Sideload to upload HTML files from my server. I’m guessing I’ll have to put the HTML data directly in my CSV file now, but if there is a smarter solution I’d love to hear about it.
Hi @Daniel_KM, I installed your latest release of the Solr plugin. Thanks for incorporating the new file extraction logic. I noticed some new configuration elements related to is_public. I added a new Solr mapping for this field, I also updated ‘Is public field’ in the Solr node config. But I’m getting an error each time I search (included below). Should I just create a new Solr index and start over?
In fact, last version of Daniel’s Solr module requires an unreleased version of Daniel’s Search module (changes integrated on June, 4th). You can use dev version to test it.
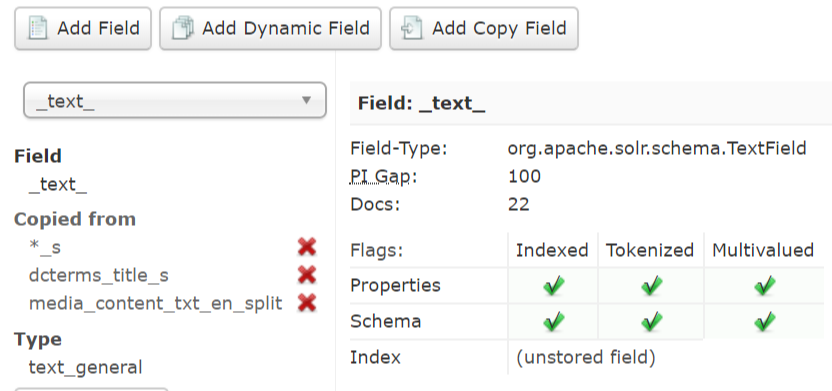
I was able to resolve the search issue by upgrading the Search module to Daniel’s dev version. But I’m not seeing the change that indexes content of text files. In fact, I am no longer able to index media content from files added via the HTML formatter, as I was before. I made no changes to my schema, but obviously a lot of other things changed with the upgrades. If you have a minute to look at the following, perhaps you will see where I’ve gone wrong.